Making CPUs Go Brrr
A Hardware Perspective to Parallel Computing
March 30, 2025·34 min read·8,607 words

You’re absolutely right. I can’t execute anything fast alone.
Everyone has their flaws & imperfections, but that’s what drives us to work together
To make up for those flaws. Together, we complete the job faster.
- Gintoki Sakata, Gintama
Parallelism is kinda like that too, bunch of workers doing there work in chunks and if needed accumulating the results to get the final answer. Wasn't always like this though. Anyways, AI is everywhere these days and there are people who build AI and people who build with AI. At the heart of it both aim for the same thing, building better and faster systems.
Most of "performance" talks end up being around optimization of GPU kernels or custom chips like Cerebras' WSM, Groq's LPU, that whole lane. CPUs barely get any attention man!! Which is so odd because a lot of what those accelerators do still runs on variations of ideas CPU systems got to first.
This blog is about going back to CPU, its architecture, and how it actually runs your code, from a single instruction all the way to throwing work across multiple cores. If you understand CPU some of the other stuff would look like a derivative.
Single Thread Execution
What are we executing?
Whenever we talk about execution we usually mean execution of a program. What is a program though? It's quite literally a set of executable instructions, for example when you write code in C you compile it to a binary which literally is a long list of assembly instructions in binary format.
So, when you write something innocent like this:
#include <stdio.h>
int main() {
int a = 5;
int b = 7;
int c = a + b;
printf("c = %d\n", c);
return 0;
}
your CPU is running a sequence like this:
Instruction Address OPs Operands
================================================
0000000100000f50 pushq %rbp
0000000100000f51 movq %rsp, %rbp
0000000100000f54 subq $0x10, %rsp
0000000100000f58 movl $0x0, -0x4(%rbp)
0000000100000f5f movl $0x5, -0x8(%rbp)
0000000100000f66 movl $0x7, -0xc(%rbp)
0000000100000f6d movl -0x8(%rbp), %eax
0000000100000f70 addl -0xc(%rbp), %eax
0000000100000f73 movl %eax, -0x10(%rbp)
0000000100000f76 leaq 0x15(%rip), %rdi
0000000100000f7d movb $0x0, %al
0000000100000f7f callq 0x100000f8c
0000000100000f84 xorl %eax, %eax
0000000100000f86 addq $0x10, %rsp
0000000100000f8a popq %rbp
0000000100000f8b retq
The speed at which this program will be executed depends on how fast your CPU works. Usually, this is measured by the clock frequency of the CPU. Clock frequency tells you how many cycles occur per second. The number of instructions per second depends on how many instructions the CPU can do per cycle.
...the Kaby Lake counterparts can achieve 4.9GHz...
It basically means Intel's Kaby Lake makes 4.9e9 cycles per second. Higher the clock frequency faster the execution. During execution the program is loaded on main memory, like RAM, CPU executes it and that's usually the end of story. The code we saw above compiles, without optimization, to roughly 15 assembly instructions.
For simplicity, let's assume each instruction takes ~1 cycle. In reality, modern CPUs can execute multiple instructions per cycle, and some instructions take longer depending on their latency and dependencies. With only ~15 instructions, the execution time is effectively negligible, on the order of a few nanoseconds.
CISC and RISC Instruction Sets▸
We casually said "each instruction takes ~1 cycle" but that overshadows a major question: what even counts as a single instruction? That depends on the Instruction Set Architecture (ISA). An ISA is basically the specification that defines what instructions, registers, and addressing modes a CPU supports. There are two major philosophies:
-
CISC (Complex Instruction Set Computing): x86. This is used by Intel and AMD, it packs a lot of operations into one instruction. Take a look at
addl -0xc(%rbp), %eaxfrom our example above. That single instruction reads a value from memory and adds it to a register. Internally the CPU might break it down into multiple atomic operations(loading, arithmetics, etc.), called micro operations (μops), that take several cycles to finish. -
RISC (Reduced Instruction Set Computing): ARM, RISC-V. This is used by Apple Silicon and takes the opposite approach. Each instruction does exactly one simple thing. That same memory read and add would be two separate instructions in ARM:
ldr w1, [x29, #-12] // load value from memory into register
add w0, w0, w1 // now add the two registers
More instructions total, but each one is dead simple and (ideally) completes in 1 cycle. This regularity also makes pipelining and ILP (which we'll get to soon) much easier to pull off in hardware.
So which wins? None, LMAO. CISC is used a lot by desktops and servers (Intel/AMD) and RISC is used a lot in mobile and Apple Silicon in your Mac. RISC-V is gaining traction in both these days but not like world domination at the time of writing. Fun fact: modern CISC processors actually decode their complex instructions into RISC-like μops internally, so the line between the two is blurrier than ever.
How does the CPU executes a program?
When you start the execution the instructions are loaded onto the main memory, these instruction need to be executed in an order so from here CPU fetches the instruction that needs to run and it executes it.
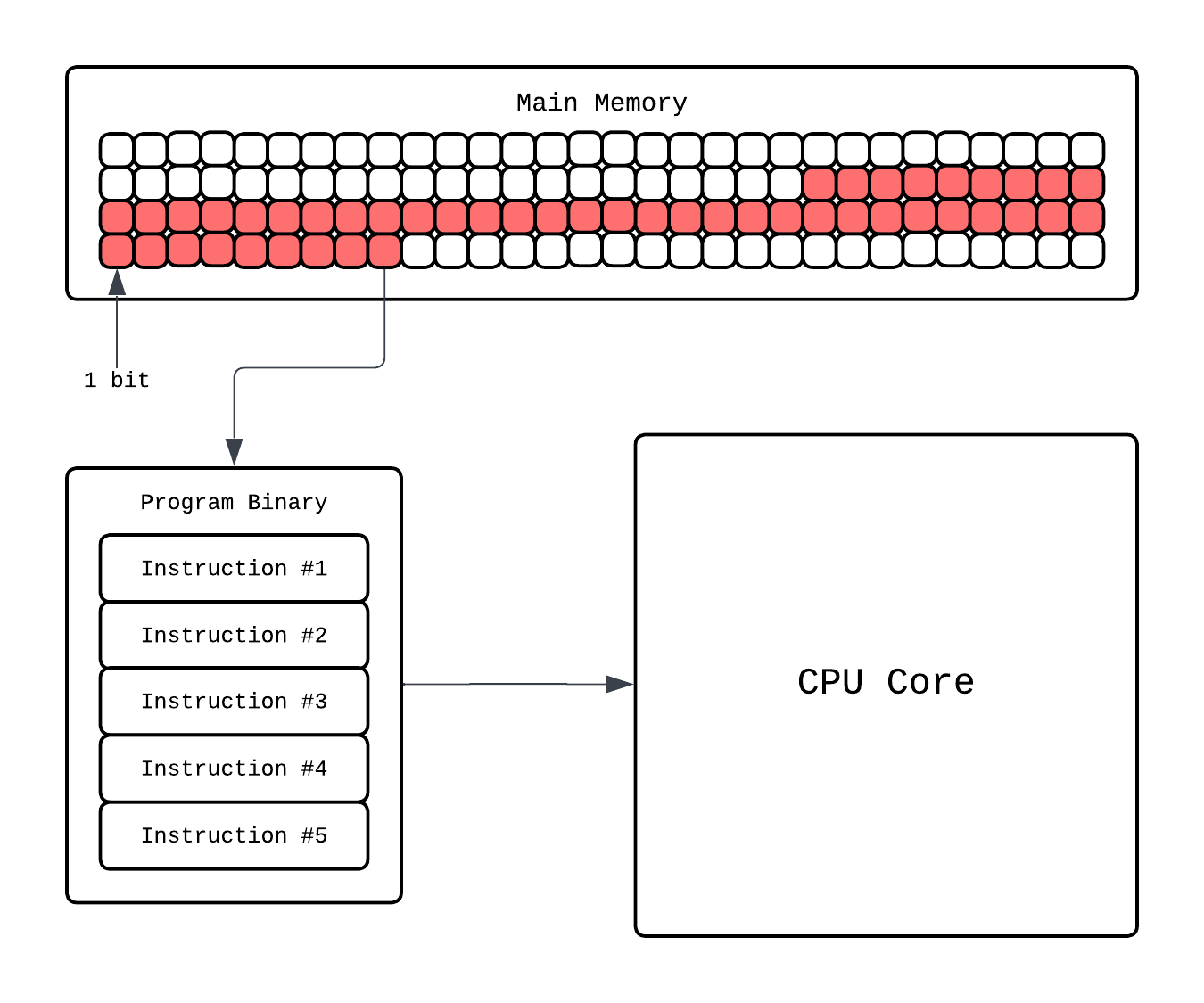
Going more in depth, in the CPU core there is a dedicated Instruction Processor that handles finding what instruction to execute and decode which component(ALUs, registers, etc.) will handle this. Then that component executes it.
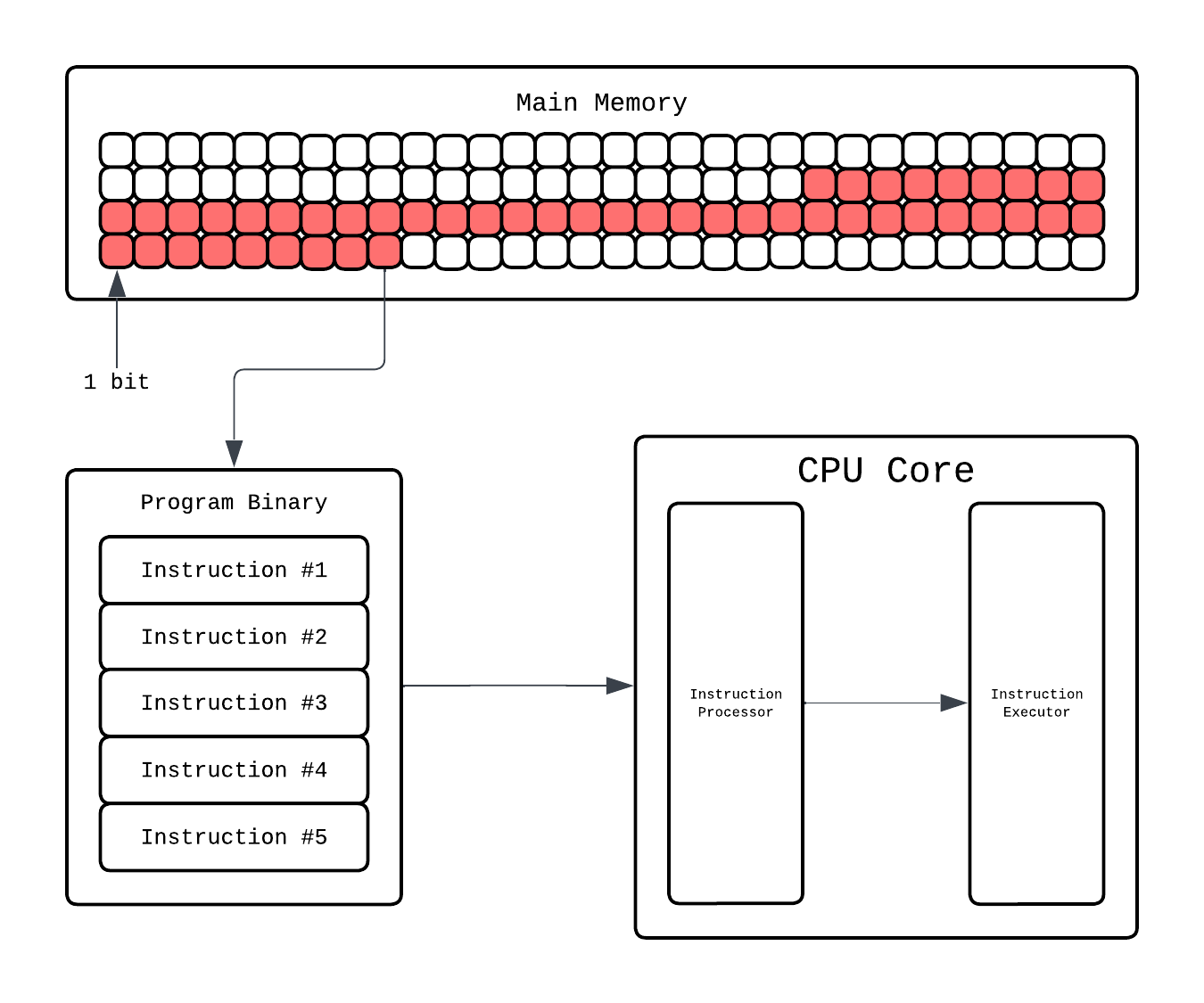
This Instruction Processor is more formally known as Control Unit. Fetching and decoding is one job of the Control Unit, it also takes the decoded command and passes it to the right hardware block. If it’s arithmetic, it’ll go to an Arithmetic Logic Unit (ALU). This is where the actual math happens: addition, subtraction, comparisons, bitwise operations. For more complex operations, like floating point multiplication, the CPU calls upon the Floating Point Unit (FPU), which specializes in arithmetics on floating point numbers.
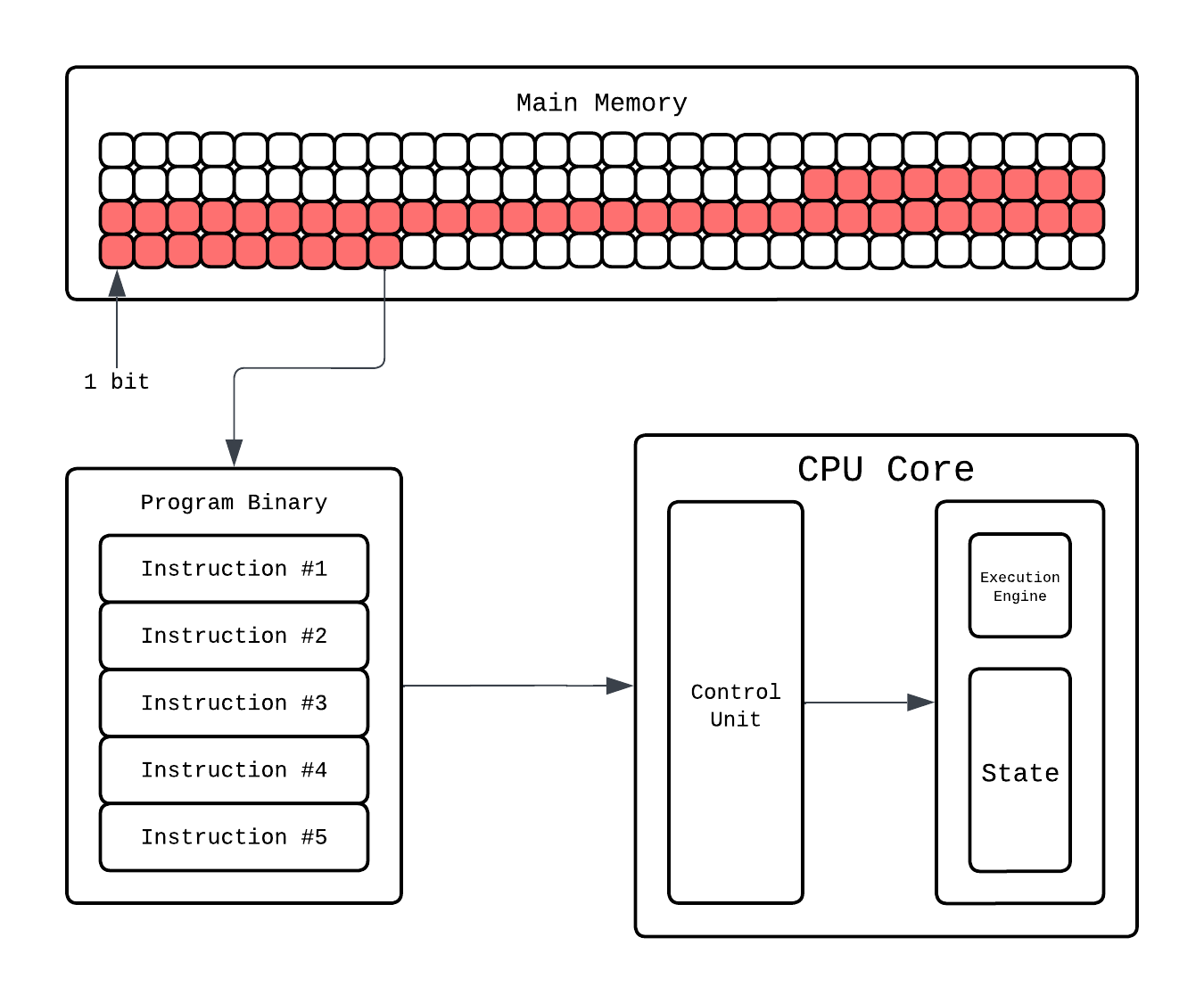
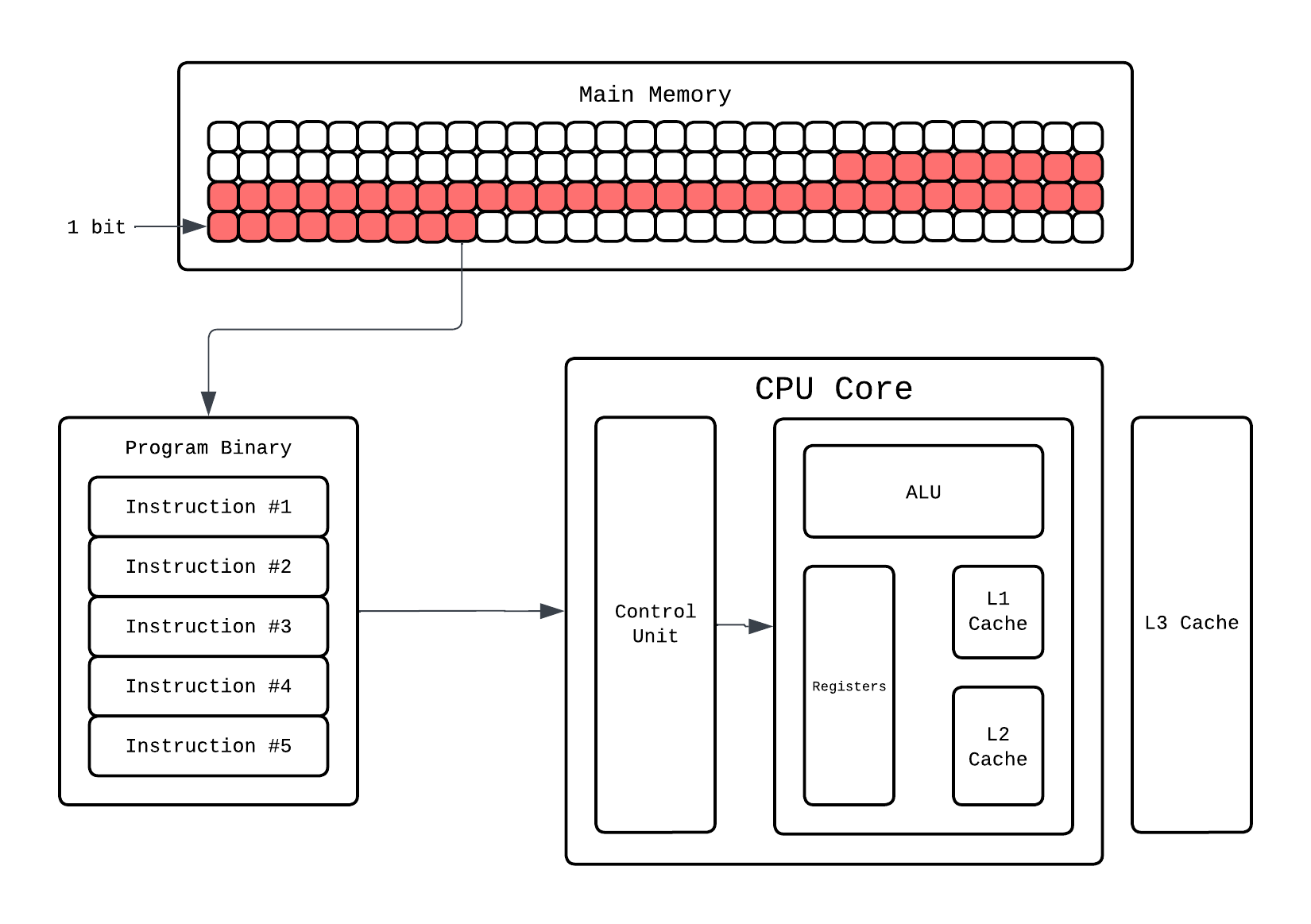
Let's say the instruction fetched is: addl -0xc(%rbp), %eax. The ALU(our execution engine) fetches the current values from registers: %rbp and %eax from the thread execution state. That’s a single instruction done, often in just one or a few cycles. Meanwhile, the control logic already begins fetching the next instruction, ensuring the core never sits idle. This overlap of stages where fetching one instruction is going on simultaneously with executing another is called Pipelining.
The execution state of the thread is stored in registers which are small but crazy fast ephemeral storage. Aside from this you have cache hierarchies that CPU manages to "save" the data so it can be fetched quickly. Why bother with different cache and memory hierarchy? If you are interested you can read the following blob.
Working and Need of Caches▸
Registers are crazy fast but have tiny memory size. Your program's data lives in RAM which can be gigabytes, but RAM is slow ~100-200 cycles per access vs ~1 cycle for a register. If the CPU went to RAM every time it needed data, it'd spend most of its time just waiting. To bridge this gap we add a small, not as small as registers, but fast memory called a cache that stores copies of recently accessed data so the CPU can grab it in a few cycles instead of hundreds. When the CPU needs a value, it checks the cache first. If it finds it there we call it a cache hit. If not we call it a cache miss, and it goes to RAM, fetches the data, and stores a copy in the cache for next time.
Now, one cache isn't enough because of a physical tradeoff: smaller memory is faster, larger memory is slower (shorter wires, fewer transistors to search through). So instead of one big cache, CPUs stack multiple levels:
| Level | Typical Size | Latency (cycles) | Shared? |
|---|---|---|---|
| L1 | 32-64 KB | ~3-5 | Per core |
| L2 | 256 KB - 2 MB | ~12-15 | Per core |
| L3 | 8-64 MB | ~30-40 | Shared across cores |
| RAM | 8-128 GB | ~100-200 | Shared across everything |
The CPU checks L1 first, then L2, then L3, and finally RAM. Each level is slower than the last because of physical distance and size. L1 is smallest and sits right next to the execution units with the shortest wires, L2 is further away and larger, and L3 is the largest, furthest out, and shared across cores so it also deals with cross-core coordination overhead. L1 and L2 are there per core, L3 is shared. Most CPUs also split L1 into L1i (instruction cache) and L1d (data cache) so fetching the next instruction and loading data can happen simultaneously.
This layering is what makes cache misses costly but survivable. A miss in L1 that hits in L2 costs ~10 extra cycles which is not great, but kinda ok still. A miss that falls through to L3 costs ~30-40 cycles. But a miss that goes all the way to RAM stalls the pipeline for 100+ cycles that's hundreds of instructions worth of time just waiting for data.
Regardless of level, all caches store data in cache lines in chunks of 64 bytes. When a miss happens, the CPU doesn't fetch just the single byte it needs it grabs the entire 64-byte line. Why? Because programs tend to access nearby memory in sequence, so by fetching a whole chunk the next few accesses are likely already cached. Each line also carries a tag (which RAM address it's a copy of) and other metadata so the cache knows what it's holding.
All of this work around what gets cached, what gets evicted and which level holds what is managed entirely by hardware. You don't get a frontend to say "put this in L1" or "pin this cache line." The cache is invisible to your program. What you can control is how you access memory, and that matters a lot because every cache miss is wasted cycles. Sequential array access plays nicely with cache lines, each 64-byte fetch covers multiple elements, so you get a burst of hits after each miss. Random pointer chasing through a linked list causes a miss on nearly every access because the next node could be anywhere in memory, blowing through all cache levels each time. Same algorithm, same Big-O, but potentially 10-100x performance difference just from cache behavior. Writing code that minimizes these misses is what people call cache-aware programming, and it's one of the bigger gains you can have for performance.
It starts by fetching the next instruction, pulling it from memory (likely from a small but incredibly quick instruction cache). Once fetched, it decodes it i.e. the CPU’s logic interprets what that instruction means: maybe it’s an addition, a comparison, or a write to memory. Finally, it executes the operation, carrying it out on the data stored in its tiny working memory called registers.
Brief history of sending signals around▸
How does control unit "passes" a command to the ALU, how does ALU "loads" from registers and how does data physically move between components? Overall, it's all done via buses which are basically sets of wires that connect different parts of the CPU. But the design and configuration of those buses that has changed a lot over the decades.
Era 1: The Three-Bus Problem. Early CPUs had three primary buses: a data bus (carries actual values), an address bus (tells the memory system where to read/write), and a control bus (carries signals like "this is a read" or "interrupt"). All components shared these wires and took turns using them. Simple, but slow since you're waiting for the bus to be free.
Era 2: Front Side Bus. Starting with Intel's Pentium Pro (1995), the CPU connected to the rest of the system through the Front Side Bus (FSB). The FSB fed into a chip called the Northbridge which handled the high-speed stuff: RAM and the graphics slots. The Northbridge then connected to a second chip called the Southbridge (I/O Controller Hub) which handled slower I/O: USB, SATA, etc. FSB speeds went from 66 MHz all the way up to over 1 GHz, but it was still fundamentally a shared bus every memory access from the CPU had to go through it.
Era 3: Integration. In 2008, Intel's Nehalem moved the memory controller into the CPU die itself (AMD actually did this earlier with the Athlon 64 in 2003). The FSB was replaced by QPI (QuickPath Interconnect), a point-to-point link and Northbridge essentially disappeared. What remained of the Southbridge became the PCH (Platform Controller Hub), connected to the CPU via DMI (Direct Media Interface).
Modern CPUs kept going with this integration trend the graphics interface and other high-speed connections also moved onto the CPU die. At this point, pretty much everything the Northbridge used to do now lives inside the CPU itself. There's no front side bus anymore because there's nothing external left to bus to. CPU has direct dedicated pins for memory and high-speed devices. The Southbridge stuff is still separate though, just not called "Southbridge" anymore.
As for how components talk to each other inside the core, i.e registers to ALU, control unit to execution units, that's all dedicated point-to-point wiring now, not shared buses. The internal bus fabric that ties together cores, caches, and the memory controller is proprietary and not publicly documented.
Unless you're under NDA designing IP for their chips, you won't see those specs. In which case reach out to me and let me know, it'll be our secret 🤫.
So that's how execution happens, but how do you make it fast? Two words, Clock...Frequency.
Making Execution go brrr
The most straightforward way to make a program run faster is to make the CPU itself run faster. Since everything inside the CPU is ultimately driven by a cycle, increasing the clock frequency means increasing how many cycles happen per second and therefore, how many instructions the CPU gets to execute.
If a CPU runs at 1 GHz clock frequency, it makes 1 billion cycles per second. At 5 GHz, it makes 5 billion cycles per second. If your program takes, say, 1 billion cycles to finish, then:
- On a 1 GHz CPU -> it takes ~1 second
- On a 5 GHz CPU -> it takes ~0.2 seconds
Execution wise, everything is same in both except one has a faster clock frequency and thus executes faster.
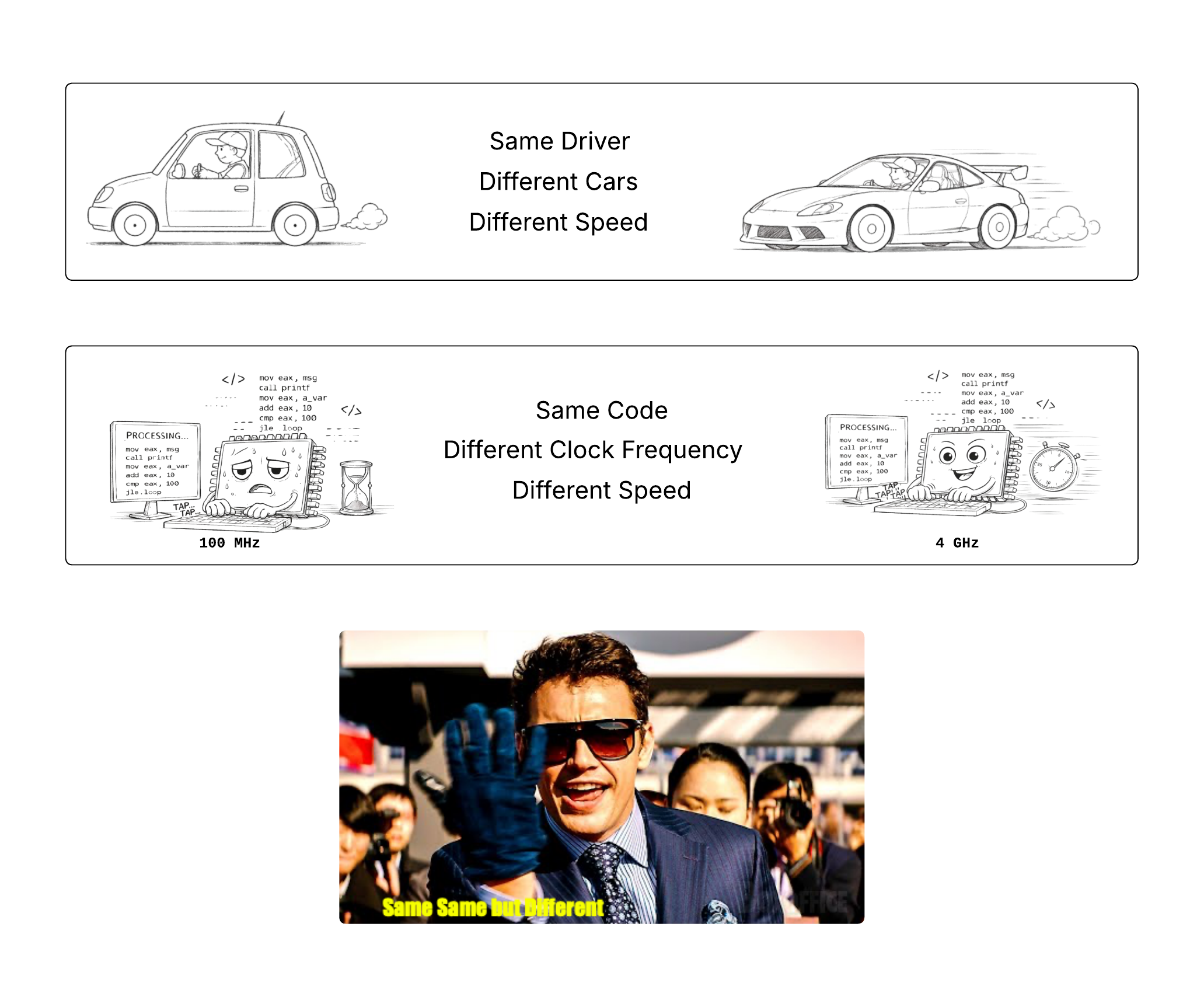
Each instruction still goes through the same fetch-decode-execute pipeline, but the pipeline itself is moving faster. Every stage completes sooner, so more instructions finish per unit time.
Historically, this is exactly how CPUs got faster for decades programmers wrote code and every year their program ran faster without them needing to do anything. Why? Because each generation just cranked the clock frequency higher and programs just got executed faster. Free Lunch FTW!!!
Sadly, that came to an end recently. To understand why it all came to an end we'll need to learn a bit more on how clock frequency can be increased and what exactly happens in cycle.
Free Lunch is Over
How TF do you increase clock frequency?
A CPU core is just a giant collection transistors. NO READ THIS CAREFULLY!!! A CPU CORE IS LITERALLY A GIANT COLLECTION OF TRANSISTORS!!!. To emphasize more and make this more concrete everything in core is a transistor:
- 1 DRAM Bit: 1 transistor (and 1 Capacitor)
- 1 SRAM Bit: 6 transistors
- 1 64-bit Registers(For storage via 6T SRAM only, no multiport logic): 6 * 64 = 384 transistors
- L1 Cache( kb): 6 * 1024 * transistors
- ALU: Millions of transistors!!!
- ...list goes on
These transistors can store two states 0 and 1. When you execute code these transistors may/or may not change their state from 0 to 1 or 1 to 0. The CPU is driven by a clock which ticks at a fixed rate. This clock period is chosen so that all transistor switching and signal propagation inside the CPU can complete before the next tick. A cycle is one tick of the CPU clock and as we saw before the number of cycles CPU can do in 1 second is clock frequency.
How TF does a CPU Clock work?▸
We keep saying "clock" but what even is a clock? A clock is anything that produces a steady, periodic tick. Your wristwatch has one, your wall clock has one, and your CPU has one too!! The job is the same everywhere: give the system a reliable sense of when to do the next thing. In a CPU, every tick tells the digital logic "move one step forward". More specifically, latch new values into registers, commit ALU results, advance the pipeline. Without it, different parts of the chip would update at random times and nothing would work.
Now, almost every clock you've interacted with wristwatches, motherboards, microcontrollers, or whatever uses a quartz crystal to generate that tick. Why quartz? Because of the piezoelectric effect!! Piezoelectricity is a physical property of certain materials where mechanical stress produces voltage, and conversely, applying voltage causes mechanical deformation. Quartz happens to exhibit this very strongly.
Why? That's more of a chemistry topic but it's mainly because quartz's crystal lattice lacks a center of symmetry. So when you compress or stretch it, the positive and negative charges in the lattice shift unevenly and end up producing a net voltage across the faces.
Back to topic, when you put a quartz crystal in a circuit and apply voltage to it the crystal physically deforms. When the voltage is removed it springs back and generates voltage in the other direction. This back-and-forth creates a vibration at the crystal's natural resonant frequency, which depends on how the crystal is cut and shaped. The circuit picks up that vibration as a repeating electrical signal. That whole setup, i.e crystal plus the driving circuit, is called a quartz crystal oscillator. We use quartz because its resonant frequency is pretty stable and way more precise than anything you could build out of analog stuff only.
But like everything in this world there is a catch. The crystal's frequency is usually in the scale of tens of MHz and CPUs these days run in GHz. We need to multiply that frequency up. So CPUs use quartz crystal oscillator to provide the stable low-frequency reference and a PLL (Phase-Locked Loop) takes that reference and scales it up to GHz speeds. The PLL has three parts:
- VCO (Voltage-Controlled Oscillator): A separate oscillator from the quartz crystal which is not stable on its own, but tunable. It generates a clock whose frequency depends on the input voltage. Higher voltage = faster clock. The crystal gives stability, the VCO gives speed.
- Frequency Divider: Takes the VCO's fast output and counts every N ticks, emitting one tick per N (e.g. one tick per 35), so a
3.5 GHzsignal becomes100 MHz. This way it can be compared against the100 MHzreference clock. - Phase Detector: Compares the divided-down VCO signal against the reference crystal signal and outputs an error voltage: "you're too fast" or "you're too slow."
That error voltage feeds back into the VCO, nudging it faster or slower until the divided-down output matches the reference exactly. At that point the loop is "locked" and the VCO is now producing a stable clock at exactly reference × multiplier. So a 100 MHz crystal with a ×35 multiplier gives you 3.5 GHz. That final signal is what defines the CPU cycle, so when we say a CPU runs at 4 GHz it means this clock circuit is generating roughly 4 billion ticks per second.
Now the states 0 and 1 are usually decided by voltage in transistors. To change the state we need to change the voltage and this is what limits the speed. So if we decide to increase this clock frequency we'll need to make this particular aspect faster. Few ways to do that are:
-
Increasing Voltage: The time for a transistor to switch depends on how fast you can charge or discharge its gate capacitance through the available current. This scales with the voltage, so higher the voltage you supply the faster the transistor will switch and smaller the cycle could be.
-
Make transistors smaller: The time of propagation inside and outside the transistors is limited by the speed and distance the electron covers. We call this gate delay. While speed of electron is something we can't accessibly change we can reduce the distance they cover by make the transistors smaller. Thus making transistors smaller in turn leads to making the signal propagation fast and turn reduces the clock period.
-
Reducing critical path: A huge chunk of delay is just wires. Signals need to travel across the chip, and those wires have resistance and capacitance. If we place things closer together and make critical paths shorter via optimal layouts, we can reduce signal propagation delays and increase clock frequency which is dependent on critical path.
So as we saw while clock frequency can be made faster and it's not as free lunch as we expected it to be. This is also the reason why the speed gains via clock frequency stopped. Let's see that in more detail!
End of Free Lunch
As I mentioned in prior sections typically for execution speedups we just relied on cranking up clock frequency. Year after year, CPUs got faster clocks and the code just ran faster without any code changes. This was nicely captured in The Free Lunch Is Over by Herb Sutter and as you can see the title says it all.
The free lunch was built on two pillars: Moore's Law and Dennard Scaling. Moore's Law predicted that transistor count would double roughly every two years, which meant chips could pack more functionality. Dennard Scaling promised that as transistors got smaller, they'd use less voltage and switch faster while maintaining constant power density. Together, these meant: making transistors smaller would use same power, switch faster, have higher clock speeds and faster execution. Free. Fucking. Lunch.

This worked smoothly from the 1970s through early 2000s. Clock speeds went from MHz to GHz. Intel's Pentium 4 in 2004 hit 3.8 GHz, and the roadmap pointed to 10 GHz by 2010. Except that never happened. Instead, clock speeds plateaued around 3-5 GHz and have stayed there ever since.

Why? Didn't we just discuss the ways to make clock speed faster?? Well yes, we talked about the ideas but each idea comes with an issue...
-
Increasing Voltage:
- The Issue: This is not free though...doing this the power consumption goes up quadratically with voltage (P ≈ V²·f) and a lot more heat is dissipated because of which the system is more prone to reaching thermal limit making the chip burn off.
-
Make transistors smaller
- The Issue:
-
As transistors get smaller their power density stays constant this is what we call Dennard Scaling. So this meant that if we made transistors smaller we can supply lower voltage and the transistors would be cool and fast. This worked...until it didn’t.
-
Dennard Scaling ignored the existence of leakage current(transistors don't fully turn off which happens because of Quantum Tunneling) and threshold voltage(minimum voltage, aside from supplied, needed to keep transistor working), both of which scaled with time. So, the power density started going up and didn't remain constant.
Quantum Tunneling▸
Effect when electrons pass through thin insulating barriers even when the device should be off.
If you wanna know why this happens this short answer explains it quite well.
-
So did we stop? No, We still make transistors smaller but they no longer give free clock speed. Not to mention how costly it is to manufacture smaller transistors and Quantum tunneling in them.
-
- The Issue:
-
Reducing critical path
- The Issue: If it was that easy it wouldn't be an issue lmao. Such Chip layouts unfortunately are usually not optimal and even in todays chips propagation delays like these dominate even the gate delay inside transistors.
Hardware folks saw this doom coming way before 2005 and had already started cooking. The core idea was what if we execute multiple instructions at the same time rather than trying to make the single instruction run fast?
Parallelism on Single Thread
Let's understand some ways of how parallelism was induced on hardware end to help facilitate concurrent instruction execution. For reference this is how our normie CPU looks like until now:
Superscalar Execution
We understand that we want to execute multiple instructions at once, but what instructions can be executed in parallel? Let's take the example of the following program:
Instruction Address OPs Operands
================================================
0000000100000f50 pushq %rbp
0000000100000f51 movq %rsp, %rbp
0000000100000f54 subq $0x10, %rsp
0000000100000f58 movl $0x0, -0x4(%rbp)
0000000100000f5f movl $0x5, -0x8(%rbp)
0000000100000f66 movl $0x7, -0xc(%rbp)
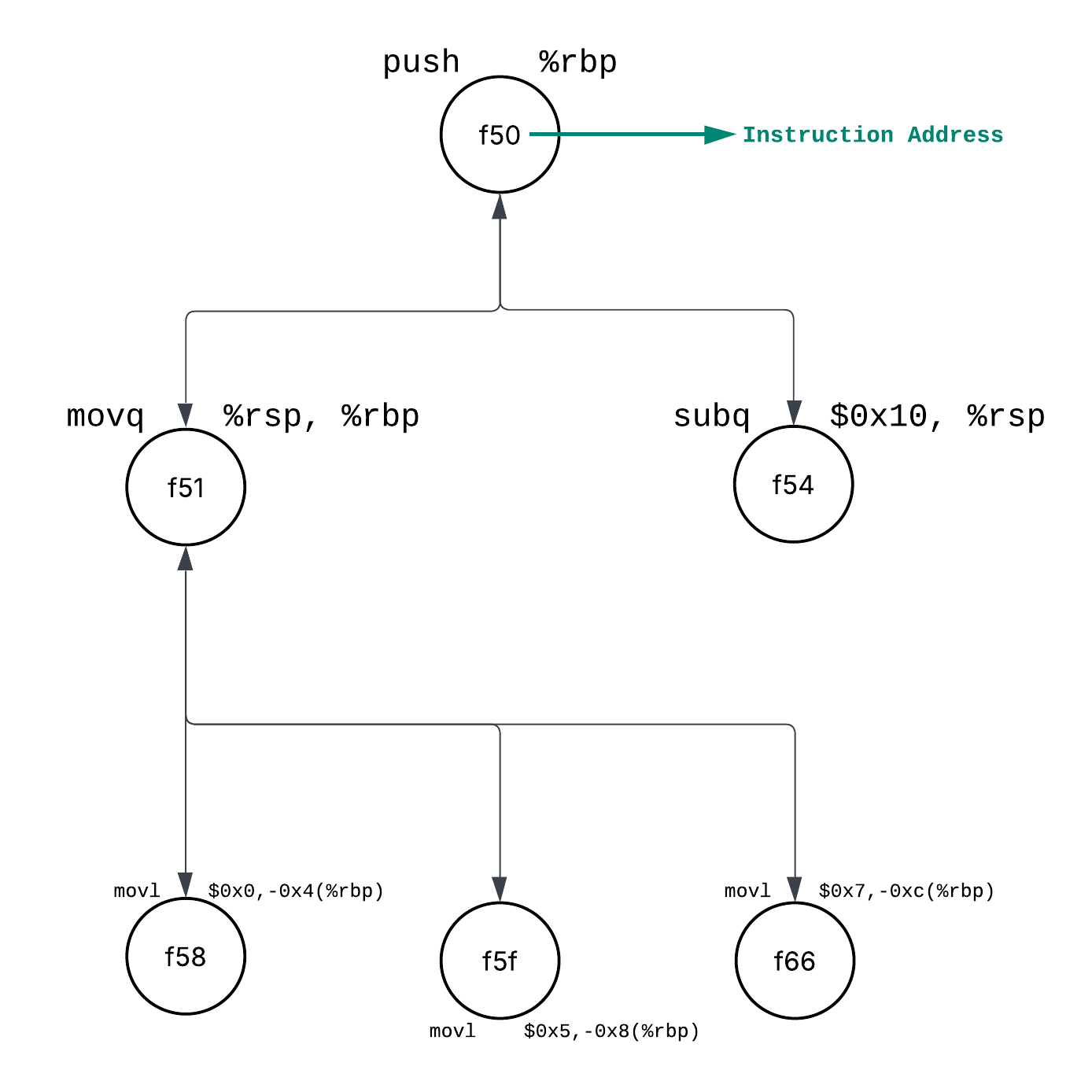
We have six instructions here we can see the second instruction depends on first instruction i.e. 2nd instruction can't run until 1st instruction is executed. 2nd and 3rd instruction can be executed parallely. Finally the last 3 instructions are also independent of each other, so these can be executed in parallel well after 2nd instruction is done.
Why are last 3 parallel when they all work on %rbp?▸
Well yes they all use %rbp as a base register but they're writing to different memory locations because mov $a, b(%rbp) in assembly copy value "a" to the address (b + what’s in %rbp):
movl $0x0, -0x4(%rbp)writes 0 to offset -0x4 from %rbpmovl $0x5, -0x8(%rbp)writes 5 to offset -0x8 from %rbpmovl $0x7, -0xc(%rbp)writes 7 to offset -0xc from %rbp
Since they write to different slots (different offsets from %rbp), there are no dependencies between them. They only read %rbp, so they can all execute simultaneously without conflicts.
So our instruction dependency/execution graph would look like this:
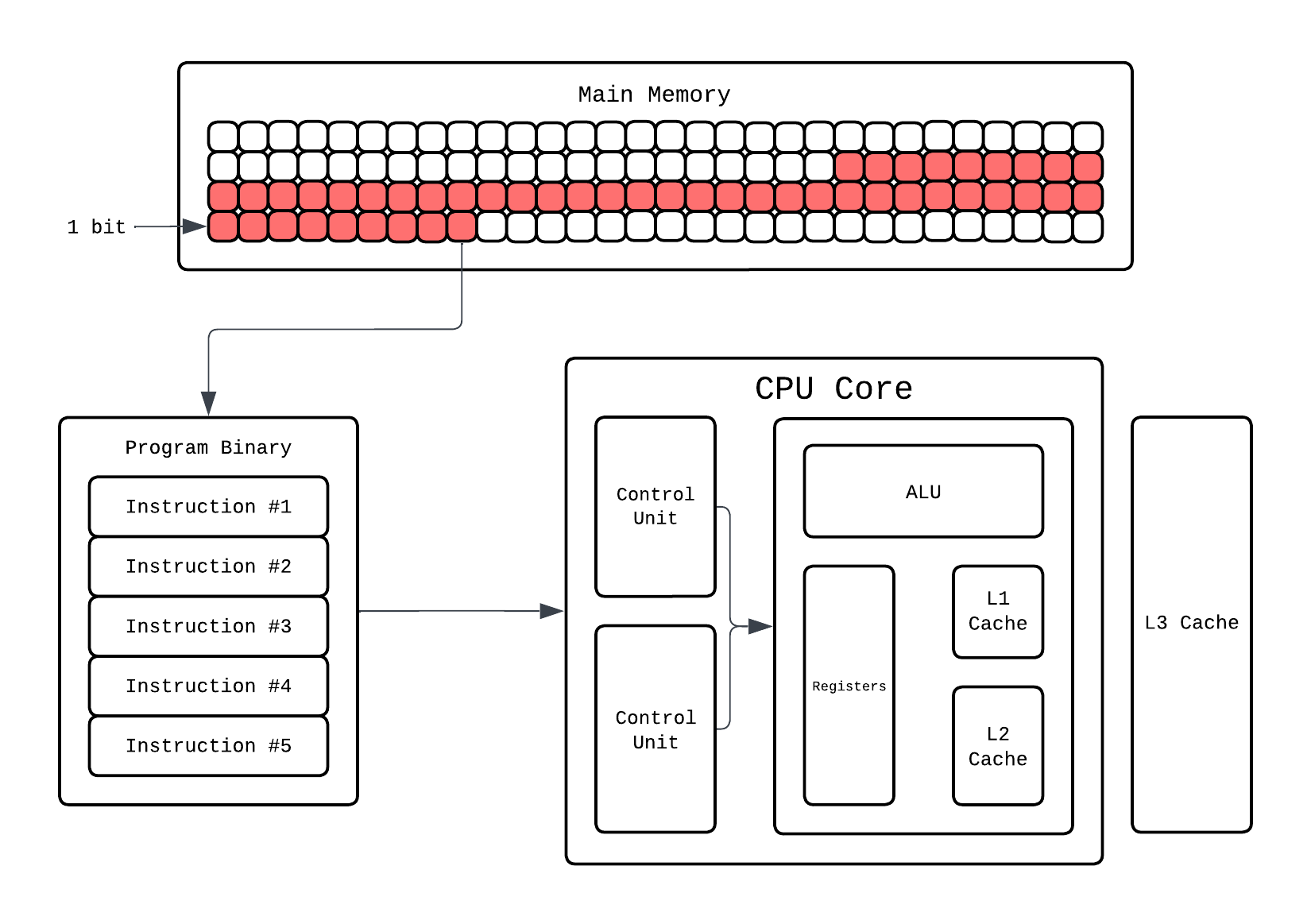
So what a CPU does is rather than fetching and decoding 1 instruction at a time it'll have multiple instructions being fetched and decoded. Hardware wise this means we'll have multiple control units at play:
So now our CPU can fetch and decode 2 instructions simultaneously thanks to multiple control units. But this still would only execute one operation, let's say arithmetic, at a time because we only have 1 ALU. For this to work, the CPU must actually have the hardware that enables execution of multiple instructions in the same cycle. How do we do that? Add more ALUs!!!!!
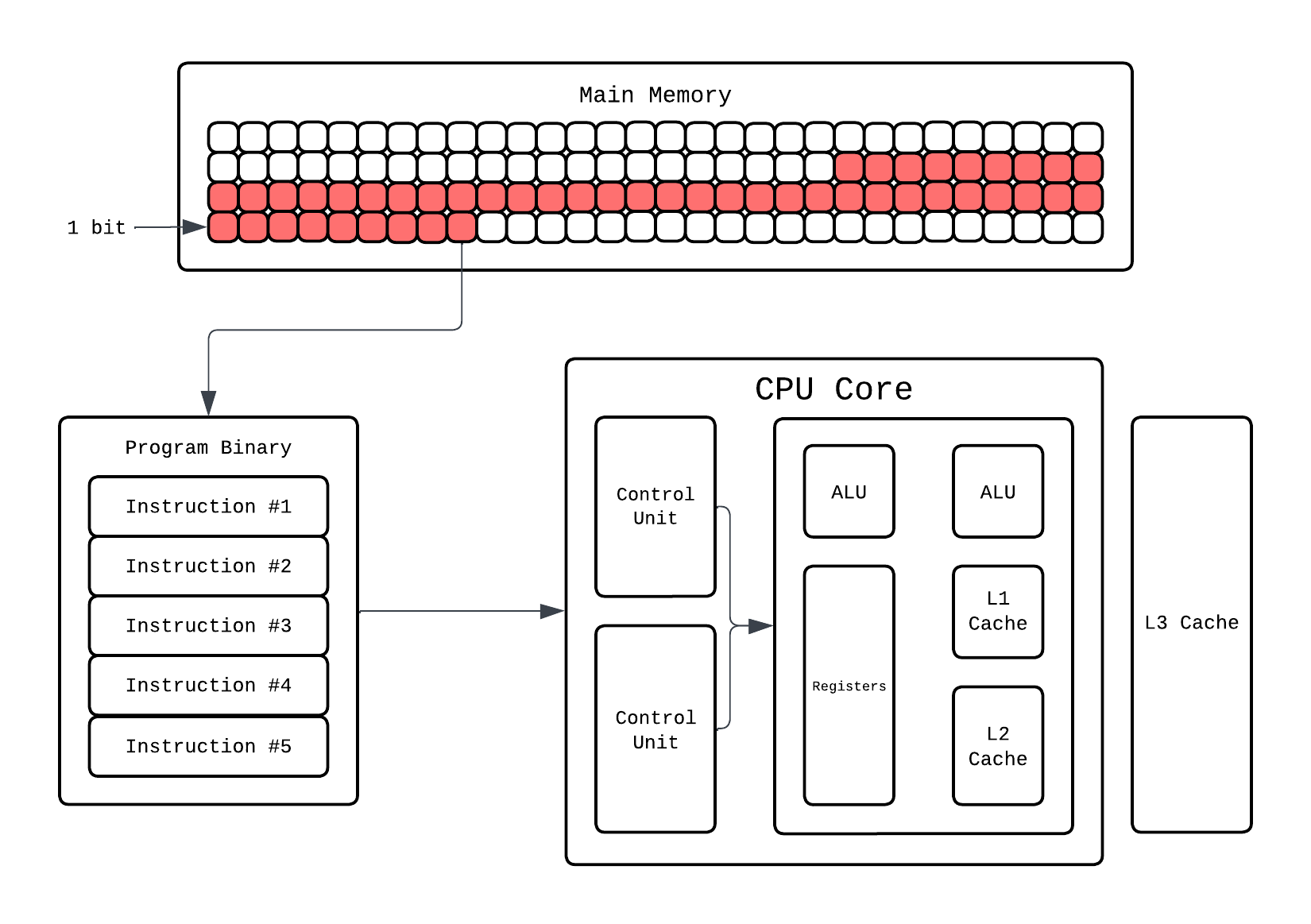
Now our CPU can fetch-decode-execute 2 instructions at the same time!! This ability to make CPU execute multiple instruction at same time is called Superscalar Execution(SE) and any dependency that stalls this is called a Hazard. If it can execute 2 instructions simultaneously it's called 2-wide superscalar, if it can execute 3 instructions simultaneously it's called 3-wide superscalar and so on!
Superscalar execution works because programs have Instruction Level Parallelism(ILP). Which means there are independent instructions that could run at the same time. ILP is a property of your code and superscalar execution is the hardware that exploits it. People often interchange them, but the nuance is there."
Superscalar Execution is the reason why 2.4Ghz CPUs with ILP are faster than 3GHz CPUs with no ILP. You might think now we've overcome the issue and we are in free lunch land again. Unfortunately, the gains with this plateaued around 2005 as well and Herb Sutter's article shows that in the graph as well. Honestly, it is fairly old as well so it wasn't like people waited for sequential execution to stagnate to implement it.
So, is single thread era done for? Well, kinda. Around early 2000, a major shift towards building concurrent systems started happening. People started utilizing thread concurrency in software more and more. But there is still one way that is still widely used to enable stuff like vectorization.
SIMD: Single Instruction, Multiple Data
Look at the following program:
#include <stdio.h>
int main() {
int a[] = {1,2,3,4,5,6};
int b[] = {1,2,3,4,5,6};
int arr_size = sizeof(a) / sizeof(int);
int c[arr_size];
for(int i = 0; i < arr_size; i++)
c[i] = a[i] + b[i];
return 0;
}
Above is an example of basic element-wise addition of two array. We are iterating over the array and adding them i.e. the add operation instruction for each element is fetched-decoded-executed. But is that the optimal way? If you think the ILP way, all the addition operations are independant of each other and the ILP graph would be:
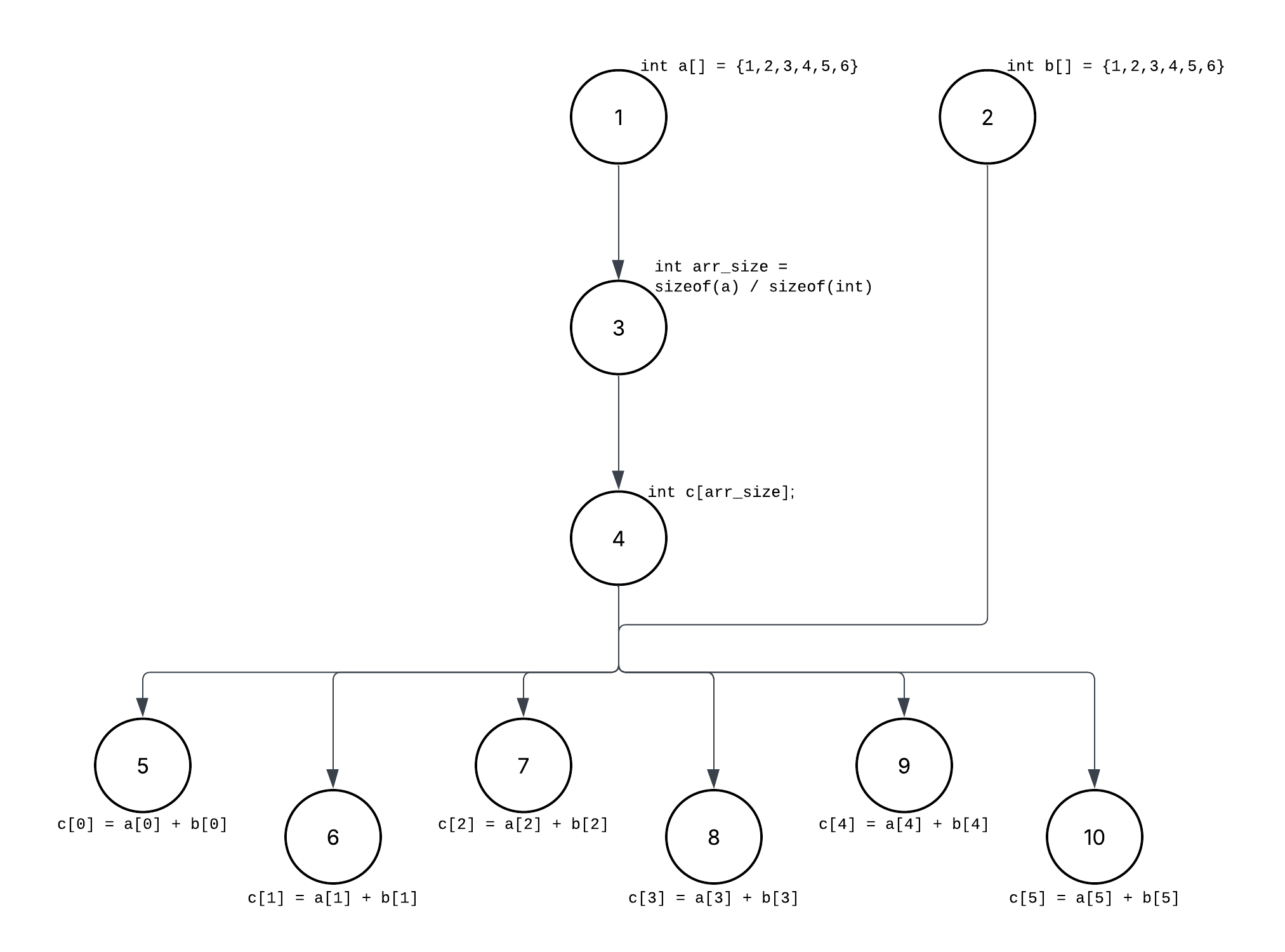
If you look at the graph, you'll notice all the element wise operations in the for loop are independent of each other and do the same operation...addition, but since we are using a for loop this'll be done 1 at a time. Even with loop unrolling and ILP, we are still fundamentally executing one arithmetic operation per data element. The CPU may issue a few of them in parallel, but we are still limited by the quantity of compute units i.e. ALUs here. What we really want is to apply the same operation to many data elements inside the execution unit itself.
This is where SIMD comes in place which executes one operation on a batch of data rather than one by one! ILP exploits parallelism across instructions. SIMD exploits parallelism inside the data. SIMD exists because it's much better to apply one operation to many data elements than to apply the same operation many times to one element each. But how do we enable it say hardware wise?
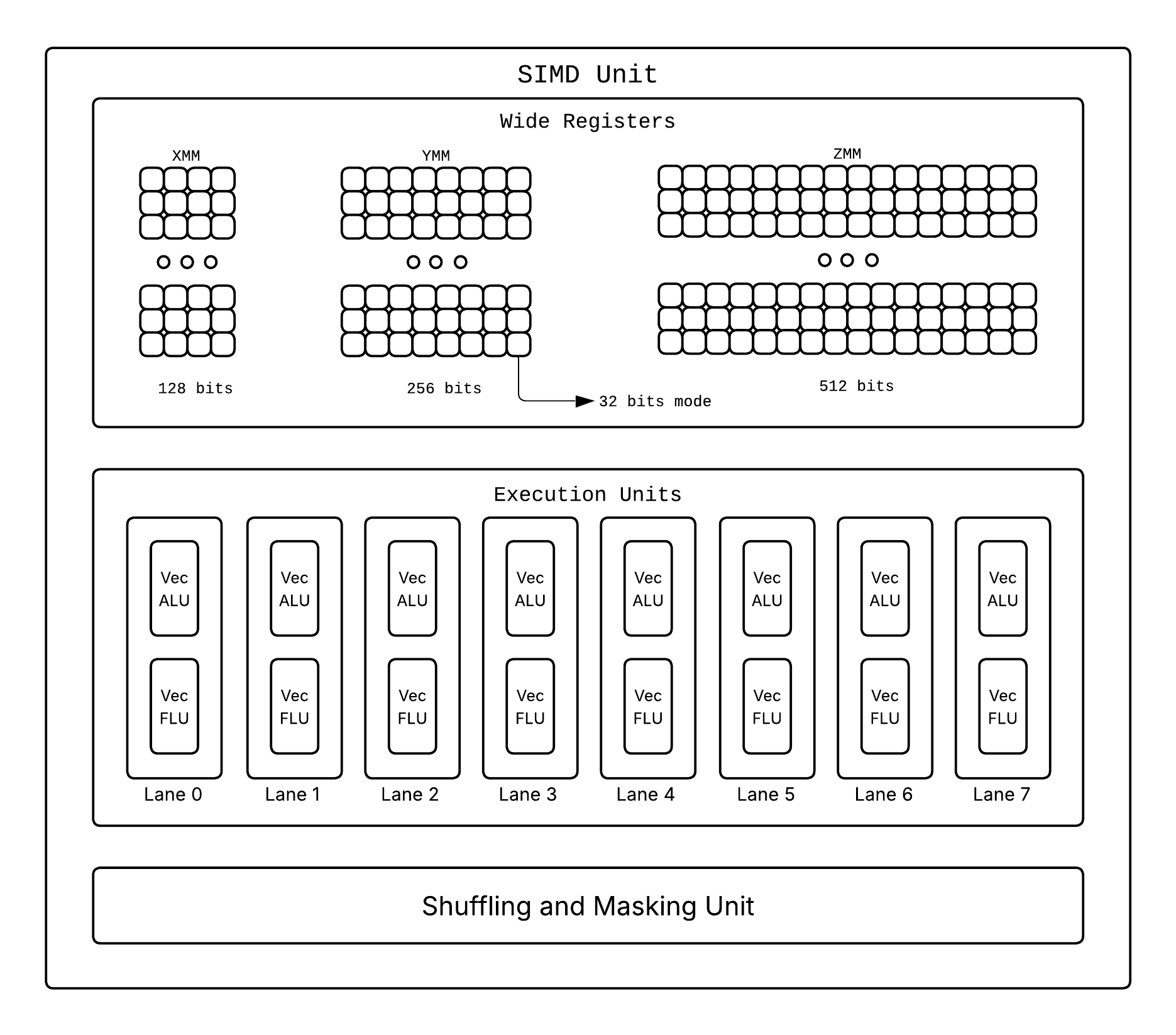
We have special SIMD units which when prompted execute one instruction that operates on multiple values at once and we use wider registers(XMM[128 bits], YMM[256 bits], ZMM[512 bits]), alongside the typical 64 bit ones, capable of storing multiple packed values instead on single ones! So if we have one such wide register of 256 bits it would be able to store: 8 values of size 32 bits, 4 values of size 64 bits, etc.
To invoke a SIMD unit operation you'll need special instructions that tell the SIMD units what to do. Different processor architectures have different SIMD instruction sets:
- x86/x64 (Intel/AMD): SSE (Streaming SIMD Extensions), AVX (Advanced Vector Extensions), AVX2, AVX-512
- ARM: NEON, SVE (Scalable Vector Extension)
- RISC-V: V extension
Let's see how our array addition example would work with SIMD:
#include <immintrin.h> // AVX intrinsics
#include <stdio.h>
int main() {
int a[] = {1, 2, 3, 4, 5, 6, 7, 8};
int b[] = {1, 2, 3, 4, 5, 6, 7, 8};
int arr_size = sizeof(a) / sizeof(int);
int c[arr_size];
// Load 8 integers (256 bits) at once into SIMD registers
__m256i vec_a = _mm256_loadu_si256((__m256i*)a);
__m256i vec_b = _mm256_loadu_si256((__m256i*)b);
// Add all 8 pairs in one instruction
__m256i vec_c = _mm256_add_epi32(vec_a, vec_b);
// Store result back
_mm256_storeu_si256((__m256i*)c, vec_c);
return 0;
}
For now let's briefly skim what this program is doing, SIMD Programming can be a different blog on its own later. In this SIMD program, instead of 8 separate addition instructions, we execute one instruction that adds 8 pairs of integers simultaneously. This is crazy efficient!!
- Without SIMD: 8 iterations, 8 separate add instructions
- With SIMD (256-bit): 1 iteration, 1 vectorized add instruction operating on 8 values
Of course it's not all perfect, you can't using conditionals without getting a performance hit due to Divergent Execution, lanes are limited, etc.
Divergent Execution▸
SIMD works great when every lane does the same thing. But what happens when you have a conditional block? Say you want to do this element-wise:
for (int i = 0; i < 8; i++) {
if (a[i] > 0)
c[i] = a[i] + b[i];
else
c[i] = 0;
}
The SIMD unit can't branch differently per lane because in SIMD it's one instruction for all lanes, that's the whole point. So instead of branching, the compiler computes both results for all lanes unconditionally. It calculates a[i] + b[i] for all 8 lanes, and it also prepares the 0 result for all 8 lanes. Then it computes a mask which lanes satisfy a[i] > 0 and uses that mask to select per lane: keep the sum where the mask is true, keep zero where the mask is false.
The wasted work is obvious: every lane computed both the addition and the zero, but only one result per lane is actually used. In the worst case (50/50 split), you're doing 2x the work compared to scalar code. This is what we call divergent execution where the lanes "want" to diverge but are forced to compute everything, discarding half the results. The more uniform your branching pattern, the less you pay. The more divergent, the closer SIMD degrades toward (or past) scalar performance.
So at this point we need to face the truth folks...Single Thread Free Lunch is done for. Good news is we got used to a new era of Parallel Computing on Multi Core Processor.
On hardware end, we scaled the number of threads a core can run and number of cores that are there. Software developers would also need to write concurrent programs that can utilize multiple cores effectively. This is where multi-threading, parallel algorithms, and concurrent programming models become essential.
Multi Threading
When you start executing a program it becomes a process, elaborating more it basically means that when you execute that program binary the OS will load the instruction to main memory as we stated before and line by line executes that program. Now this program in execution works with registers and ALUs and Caches and what not. Basically it needs resources to work, when a process is created it is allocated resources it can use to execute.
Now when the execution is actually happening, the process needs a way to keep track of where it is in the program and what it's doing. This is where threads come in. A thread is the smallest unit of execution within a process. When a process is created, it starts with at least one thread (called the main thread) that runs through the program's instructions. So when you execute this program:
#include <stdio.h>
int main() {
int a[] = {1,2,3,4,5,6};
int b[] = {1,2,3,4,5,6};
int arr_size = sizeof(a) / sizeof(int);
int c[arr_size];
int d[arr_size];
for(int i = 0; i < arr_size; i++)
c[i] = a[i] + b[i];
// Yes I know this is dumb
for(int i = 0; i < arr_size; i++)
d[i] = a[i] * b[i];
return 0;
}
The OS will spawn one program with one thread to execute this. But what does it mean to execute something on same thread? Each program needs to keep track of three things during execution:
- Program Counter that tracks the address of the next instruction to execute. This is usually stored in the
ripregister. - Program Stack that holds information about variables, methods etc. The top of the stack is tracked by the
rspregister. - Registers that hold the values the thread is working on, like operands for arithmetic, loop counters, addresses, etc.
Oki! So basically executing on same thread means working on same register or more specifically same state of registers. When a program is being executed on a thread the state and storage of the register keeps changing, this "state of registers" is called execution context. So unless your hardware can support existence of multiple execution contexts on it you can't truly do multithreading. Despite that, it is possible to have multiple software threads each doing a different task on different execution context:
#include <stdio.h>
#include <pthread.h>
typedef struct {
int *a;
int *b;
int *out;
int n;
} Args;
void *add(void *p) {
Args *x = p;
for (int i = 0; i < x->n; i++)
x->out[i] = x->a[i] + x->b[i];
return 0;
}
void *mul(void *p) {
Args *x = p;
for (int i = 0; i < x->n; i++)
x->out[i] = x->a[i] * x->b[i];
return 0;
}
int main() {
int a[] = {1,2,3,4,5,6};
int b[] = {1,2,3,4,5,6};
int arr_size = sizeof(a)/sizeof(a[0]);
int c[arr_size];
int d[arr_size];
Args add_args = {a, b, c, arr_size};
Args mul_args = {a, b, d, arr_size};
pthread_t t1, t2;
pthread_create(&t1, 0, add, &add_args);
pthread_create(&t2, 0, mul, &mul_args);
pthread_join(t1, 0);
pthread_join(t2, 0);
return 0;
}
In the program above the OS will still spawn a single process and executed instruction on same thread. But how are separate execution contexts for both the threads being handled? On software end we do spawn two threads, but on hardware end only one gets executed at time and the execution switches rapidly between thread 1 and thread 2. For example, when the threads are spawned there will be a queue that tell which thread can execute for some amount of cycles.
This switch happens frequently and very fast. In each switch the execution context of the old thread is saved and the execution context of the new thread is loaded and then finally the thread starts executing.
This switching is what we call Context Switching and is usually handled by the OS scheduler. Context switching has an extra overhead from saving and loading the execution context which is why having too many threads can actually slow execution.
Info▸
Note that ILP and SIMD don't disappear in multithreading, they work alongside it! Each thread can still execute multiple instructions per cycle (ILP) and process data in parallel using SIMD instructions. Multithreading adds another layer of parallelism on top of these existing mechanisms to execute different, and potentially independent, tasks simultaneously.
This is not the only overhead that can delay execution in multithread setup. Often these spawned thread might end up fighting each other for same resource like cache, memory, etc. and cause even more delays. This is what we call Resource Contention. Reminds me of me and my sister fighting for TV remote...good days.

Synchronization▸
Resource contention isn't just about hardware resources like ALUs and cache. Threads often need to access the same data, and that's where things get really dangerous. Say two threads both try to increment a shared counter:
int counter = 0;
void *increment(void *arg) {
for (int i = 0; i < 100000; i++)
counter++; // read -> modify -> write
return NULL;
}
If two threads run increment simultaneously, you'd expect counter to end up at 200000. But it won't. Thread A reads counter (say 5), thread B also reads it (5), both add 1, both write back 6. You lost an increment. Run this enough times and you'll get a different wrong answer each time. This is a race condition, where the result depends on the timing of execution, which is non-deterministic.
The counter++ line is the problem. It looks like one operation but it's actually three: read, modify, write. The piece of code that accesses shared data like this and must not be executed by multiple threads at the same time is called a critical section. The goal of synchronization is to ensure only one thread is inside a critical section at any given time.
The most basic way to protect a critical section is with a lock. Before entering the critical section, a thread acquires the lock. If no one else holds it, the thread proceeds. If another thread already holds it, the requesting thread blocks (waits) until the lock is released. Once done, it releases the lock so others can enter:
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
void *increment(void *arg) {
for (int i = 0; i < 100000; i++) {
pthread_mutex_lock(&lock); // acquire
counter++; // critical section
pthread_mutex_unlock(&lock); // release
}
return NULL;
}
Now counter will always be 200000. The mutex (mutual exclusion lock) guarantees only one thread is in the critical section at a time. Simple and safe, but if you hold it too long you serialize your "parallel" program back into sequential execution.
Mutexes aren't the only option though. In practice, locks come in different flavors:
- Semaphore: A generalized lock that allows up to N threads to access a resource simultaneously. A mutex is basically a semaphore with N=1. Useful when you have a pool of resources (like database connections) and can allow limited concurrent access.
- Atomic Operations: Instead of using a lock at all, some operations can be made atomic at the hardware level, meaning they complete in a single indivisible step. Our counter example could just use
atomic_fetch_add(&counter, 1)which increments and returns the old value in one instruction that no other thread can interrupt. Much faster than a mutex for simple operations, but limited to what the hardware supports (usually single reads, writes, or read-modify-writes on aligned values).
As you can see there is a tradeoff here. Too little synchronization gives you race conditions and corrupted data. Too much synchronization kills parallelism because threads spend all their time waiting for locks. Getting this balance right is one of the hardest parts of concurrent programming, and bugs from getting it wrong (deadlocks, livelocks, data races) are kinda difficult to reproduce and debug because they depend on timing.
Why am I telling you all this though? To realize that scaling up software thread is not always the answer to making things fast. So getting back to the pthread program we have two threads running on our CPU which right now can only run one thread at a time via Context Switching. This is because our CPU only has enough registers to hold execution context of one thread at a time. So do we make this CPU Run multiple threads then? Occam's Razor, just add more registers:
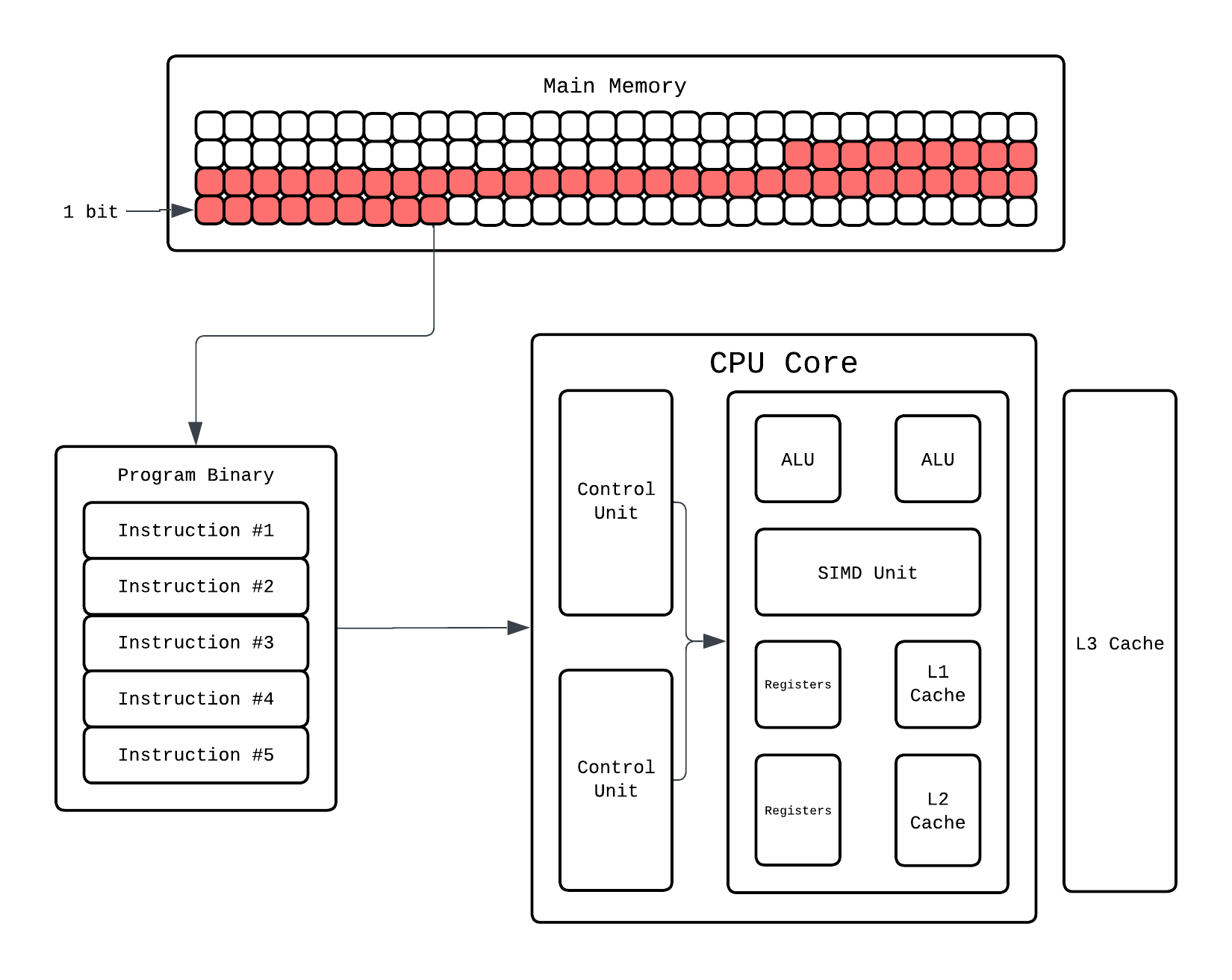
With enough registers to hold two execution context we can now run two threads at the same time now! Our CPU now has two hardware threads. This way of making core support running more threads, like via scaling components like registers, is called Hyperthreading. But there is one issue, yes we can run two threads at a time which fixed Context Switching but we still can have contention since they still share ALU.
In such situations where scaling execution components is more beneficial than splitting the task across the threads we can leverage MultiProcessing.
Multi Processing
When we do multithreading on a single core, the process for executing program is spawned and multiple threads inside that process are spawned to do certain task. Now our CPU until now can only handle two threads at a time but there is no software limit since context switching handles these multi thread execution for us. We understand threads and what they do but what is a process?
You'll find people saying "a program in execution is a process". But what does it mean? We know during the execution the program is loaded into memory and then executed in CPU potentially involving ILP, context switching etc. These executions need resources like ALU for computing, registers and memory for data related instructions, etc. When you execute the program, the OS will allocate these resources to the running program, and this allocation of resources bundled with the execution is what we call a process.
But what does allocation mean? When you spawn a process, the OS needs to remember what resources the process owns. The OS maintains this information in a data structure called the Process Control Block (PCB). Each process has its own PCB that stores:
- Process ID (PID)
- Process state (running, waiting, etc.)
- Program counter and register values
- Memory management information (page tables, memory limits)
- Open file descriptors
- Scheduling information (priority, CPU time used)
- Parent process ID
So instead of having one process with multiple threads fighting over shared resources, we can just spawn multiple processes right? Each process would get its own copy of everything. This is what we call multiprocessing!
However, unless hardware can support execution of multiple processes at once we are essentially going back to context switching. For context switching between processes, OS saves the process's execution context to its PCB and loads the next process's execution context from its PCB. So what would it take to execute multiple processes simultaneously on a CPU? Again, Occam's Razor, just add more cores!!
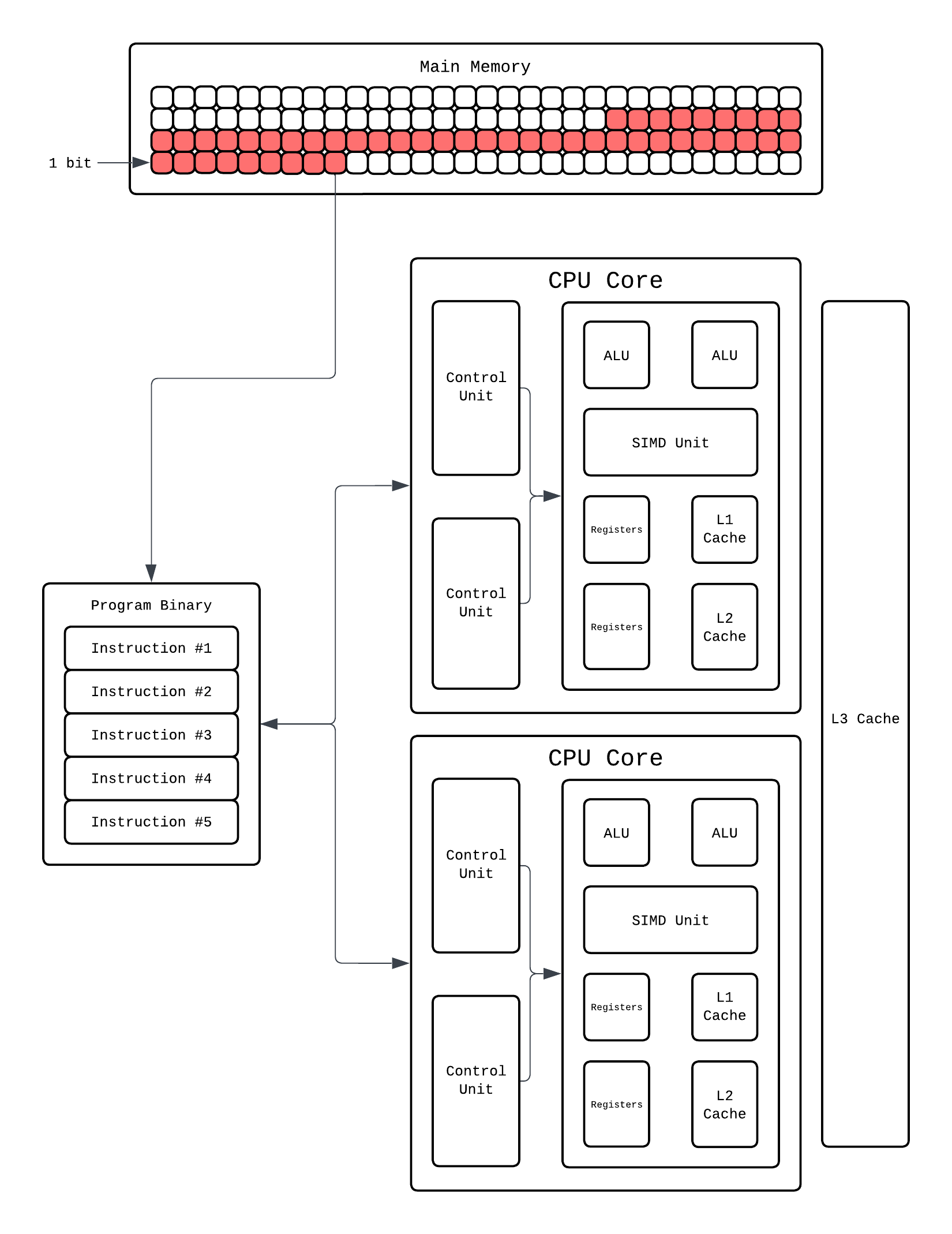
Instead of having one core juggling multiple processes via context switching, we just add more cores! Each core is essentially a complete CPU with its own control units, ALUs, registers, and L1/L2 caches. Now Process 1 can run on Core 1 and Process 2 can run on Core 2 truly in parallel. No context switching needed between processes, no fighting over ALUs.
But wait, how does this even work? We now have multiple processes running, probably across different cores, but they all share the same physical RAM. For Example, when Process A uses memory address 0x1000, how does the OS ensure it doesn't accidentally access Process B's data at that same address? This isn't even a multi core problem, even two processes on a single core via context switching can have this issue. Solution is simple, we'll use fake memory or more formally have a Virtual Memory that maps to actual physical memory.
More specifically, each process doesn't actually work with physical RAM addresses directly. Instead, it works with virtual addresses that the CPU translates to physical addresses using something called page table. So when Process A accesses address 0x1000, it might map to physical address 0x5000, while Process B's address 0x1000 maps to 0x8000. Different physical locations, same virtual address.
Virtual Memory and Demand Paging▸
So we said each process gets its own virtual address space and the CPU translates virtual addresses to physical ones. But how does this all happen? There's a piece of hardware inside the CPU called the MMU (Memory Management Unit). On every memory access, your program says "give me the value at address 0x1000" which MMU catches and translates 0x1000 to whatever physical address it actually maps to, and fetches from there. The program never sees a physical address.
Ofcourse for this translation MMU needs a lookup table to know which virtual address maps where. That table is called a page table. The OS divides virtual memory and physical memory into fixed-size chunks called pages (typically 4 KB). The page table is a data structure that maps each virtual page to a physical page called a frame. Each process gets their own page table. When the CPU accesses a virtual address, the hardware splits it into two parts: which page it belongs to, and where within that page the byte sits. It looks up the page number in the table to find the physical frame, and the position within the page stays the same since pages and frames are the same size.
This lookup happens on every single memory access, so it needs to be fast. The CPU has a small dedicated cache for page table entries called the Translation Lookaside Buffer(TLB). If the mapping is in the TLB, translation takes 1-2 cycles. If not the CPU has to walk the page table in memory, which can take tens of cycles.
Now this is where demand paging comes in. When a process starts, the OS doesn't load all of its data into physical RAM. It sets up the page table entries but marks most pages as "not present." When the process first tries to access one of those pages, the CPU triggers a page fault, the OS steps in, loads that page from disk into a physical frame, updates the page table entry, and lets the process continue. The program never knows this happened.
This is pretty dope!!! Because it means you can run programs whose total memory footprint is larger than your actual RAM!!! The OS just keeps the actively used pages in RAM and leaves the rest on disk. If RAM fills up, it picks a page to swap out by writing to disk using some method similar to cache eviction, making room for the newly needed page. The tradeoff is if your program's working set doesn't fit in RAM, you start hitting disk on every page fault, and disk is millions of times slower than RAM. This is called thrashing and it will drag your system to a halt.
To do multiprocessing in C, we use a system call named fork which creates a new process to execute the instruction coming after it. Let's check out an example:
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>
int main() {
int a[] = {1,2,3,4,5,6};
int b[] = {1,2,3,4,5,6};
int arr_size = sizeof(a)/sizeof(a[0]);
pid_t pid = fork();
if (pid == 0) {
// Child process: do addition
int c[arr_size];
for(int i = 0; i < arr_size; i++)
c[i] = a[i] + b[i];
return 0;
} else {
// Parent process: do multiplication
int d[arr_size];
for(int i = 0; i < arr_size; i++)
d[i] = a[i] * b[i];
wait(NULL);
return 0;
}
}
Now we have two independent processes potentially running on two different cores with zero contention for registers or ALUs! Modern CPUs typically have 4, 8, 16, or even more cores. And remember hyperthreading? Each of those cores can often run 2 hardware threads simultaneously. So an 8-core CPU with hyperthreading can execute 16 threads at the same time!
It was a big ride friends but finally, finally we solved parallelism, did we? Well no... Parallel programming is not a free ride, you don't magically see gains from SIMD, multi-threading or whatever. It all comes at a cost of overheads, code complexity, and multiple pitfalls. Good news is that if you learn good parallel programming all this is usually managable.
From Me to You
After all this blabbering of mine, that you all have read patiently(hopefully), we finally came to conclusion that there is no "one way" to speeding up program with parallel programming. That doesn't mean it's bad it just means that you'll need to evaluate the needs of the program to understand the needs of program and the hardware you'll be working with.
SIMD, ILP, multithreading, multiprocessing, GPUs, whatever are just tools and like every tool, if you use them wrong, you can very easily make things slower instead of faster. This blog aimed to familiarize you how to understand concurrency from machine perspective. Maybe in future blogs we can explore more on how to do good parallel programming :). Until then ✌️.